
Computer Vision Algorithm Implementations
Year: 2015
I implemented, experimented, and analyzed the results three foundational computer vision algorithms: GrabCut Image Segmentation, TLD online-single target tracker, and R-CNN object detector. These implementations and analyses were performed to complete CS231B: The Cutting Edge of Computer Vision with Professor Fei-Fei Li at Stanford University.
GrabCut Image Segmentation
Abstract
The goal of foreground-background segmentation is to divide the pixels of an image into two sections, foreground and background. Foreground-background segmentation is a challenging task, and has many applications in object recognition and classification. A successful segmentation requires knowledge of both local features and global features in an image. GrabCut segments the image by minimizing an energy equation that balances both local and global relationships between pixels.
We implement GrabCut and experiment with three extensions. We try varying the number of Gaussian Mixture Model (GMM) components used, reinitializing GMM components after a few iterations, and restricting the background GMM to pixels within the bounding box.








Conclusion
From our three experiments we see that the number of GMM components used can have a large effect on the final segmentation for certain images. Moreover, reinitializing GMM components after a few iterations can stabilize the segmentations. Finally, we achieve our best result of 96.94% accuracy and 87.71% Jaccard similarity when we constrain the background model to only the pixels within the bounding box on all but the initial iteration. This approach allows the model to better represent the local color distribution around the object. Nevertheless, some images still may not segment well, because of similarities between the foreground and background. In these cases, we could further improve our segmentations by including user interaction.
TLD Online-Single Target Tracker
Online tracking of an object in video is a difficult task because the objects appearance can change a lot across frames. For example, the object might undergo changes in illumination, rotation, or occlusion. A successful system must learn to adapt to these changes in order to continue tracking the object.

Kalal et al propose a system that combines tracking and detection to follow an object. They track the object between frames using the Lucas-Kanade optical flow tracker. The tracker works well if there is minimal object motion between frames, and can fail if the object moves too quickly or goes out of frame. The detector searches for the object in every frame by comparing individual patches to the learned object model. The comparison are performed with fern hashing and nearest neighbor classifiers. After each iteration, the integrator compares the confidences of tracker and detector’s object location estimates to choose a final bounding box. Also, the object model is updated by sampling a set of positive patches around the object’s estimated location and a set of negative patches from the background of the image. This learning step allows the object model to adapt to changes in appearance from frame to frame.

We implement the TLD tracker and experiment with a few extensions including varying the fern dimensions and the number of ferns in the ensemble, replacing the fern classifier with an SVM, and using Histogram of Oriented Gradient (HOG) features to represent each image patch.
R-CNN Object Detector
Object detection is a challenging task for many reasons. For example, objects of one class may come in different shapes, colors, positions and poses. An effective object detector must detect objects of the same class in spite of intra-class variation, while at the same time ignoring out-of-class objects. Recently Convolutional Neural Networks (CNNs) have become more popular for describing objects as the variation among a class can be learnt through training.
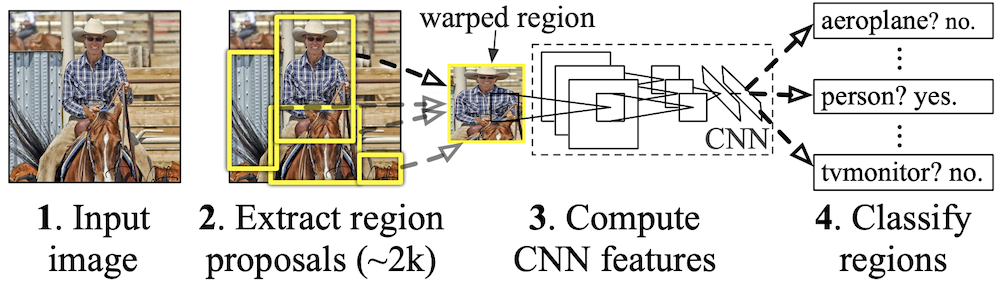
The R-CNN achieves strong object detection performance by using selective search to retrieve bounding box proposals, a pre-trained CNN to extract feature vectors from each region, and an SVM classifier. The bounding box proposals are refined using ridge regression, and finally non-maximal suppression is applied to the bounding boxes to achieve a single prediction per object instance.
Technologies
- Python
- C++
- Matlab