
Sampling Strategies for Deep Reinforcement Learning
Year: 2015

Authors
Bryan Anenberg and Bharad Raghavan
Abstract
Q-learning algorithms that employ experience replay sample experiences from the replay memory. The quality of the experiences sampled dramatically impacts the training of the algorithm. We extend the Deep-Q-Learning algorithm of Mnih et. al by considering various strategies to better sample experiences when training the agent. We evaluate the impact each sampling strategy has on the learning rate and performance of the agent by training the agent to play five Atari 2600 games.
Resources
Sampling Strategies
It is important that the sampling strategy selects a minibatch of experiences that the Q-network will learn the most from. Identifying which experiences are the best for learning isn’t obvious. We experiment with five different sampling techniques to determine which strategy most improves the learning rate and accuracy of the agent.
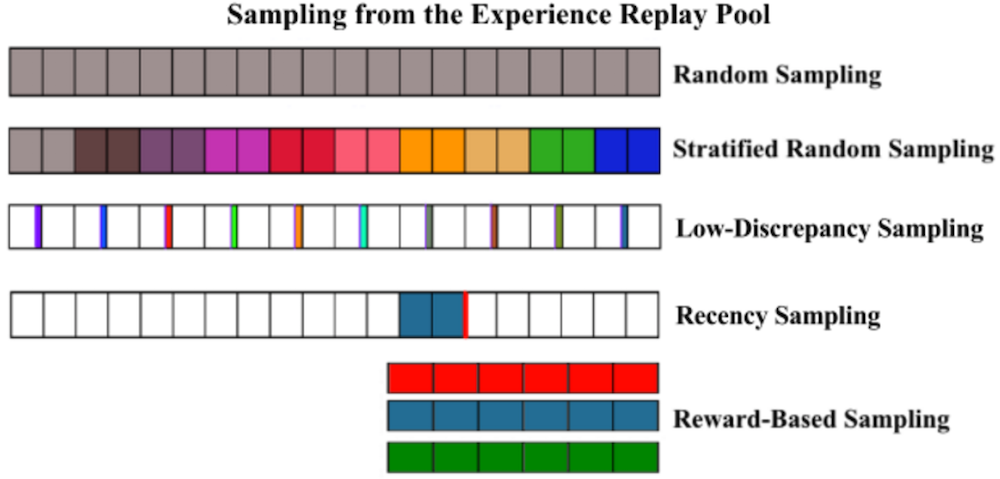
Baseline: Standard Random Sampling
The baseline sampling strategy samples a minibatch of size with uniform probability across the entire replay memory.
Stratified Random Sampling.
In stratified random sampling, the replay memory is divided into distinct, non-overlapping groups. Each group contains temporally continuous experiences from a distinct period of time. The mini-batch is formed by randomly sampling one experience from each group. Stratified random sampling yields more temporally diverse mini-batches than standard random sampling.
Low-Discrepancy Sampling
Low-discrepancy sampling samples numbers based on a low-discrepancy sequence rather than a pseudo-random number generator. While a pseudo-random number generator samples numbers in a given range with uniform probability, a low-discrepancy sequence deterministically generates numbers that are uniformly spaced out within a given range. Low-discrepancy sampling generates numbers that both uniformly span a given range and are evenly spaced out amongst themselves.
Recency Sampling
Recency sampling generates a mini-batch of size by selecting the x most recent experiences from the replay memory. These samples are all highly correlated since consecutive frames are often similar.
Reward Based Sampling
Every experience in the replay memory possesses a reward in in the range of -1 to 1. Reward-based sampling samples experiences uniformly based on their reward value. Specifically, the replay memory is quantized into three buckets: low-reward , medium-reward , and high-reward . Experiences are sampled by randomly selecting one of the three buckets and then uniformly randomly sampling an experience from that pool. This process is repeated until there are experiences in the minibatch.
Conclusion
After testing the sampling strategies on five games, it was discovered that on the whole, no sampling strategy greatly improved upon the baseline, and the only sampling strategy found to perform consistently on par with or slightly better than Uniform Random Sampling was Stratified Random Sampling.
Technologies
- Python
- Lua