
Oculus LipSync - Lip Animation from Audio
Year: 2017 - 2019
At Oculus I contributed to the LipSync project, an effort to build technology capable of driving expressive facial animation in real-time from spoken word in any language. At the core of this technology are deep neural networks trained on the audio input stream to predict viseme lip shapes, and audio expressions such as laughter. My primary contribution to the project was leading the research and development of audio event detector capable of identifying laughter from audio signal alone.
Facial Animation from Audio
Oculus LipSync provides developers with the tools to build engaging social experiences in virtual reality with in-game avatars that feel alive, whose faces animate in real-time to match the player’s actual expression.
Powered by Deep Learning
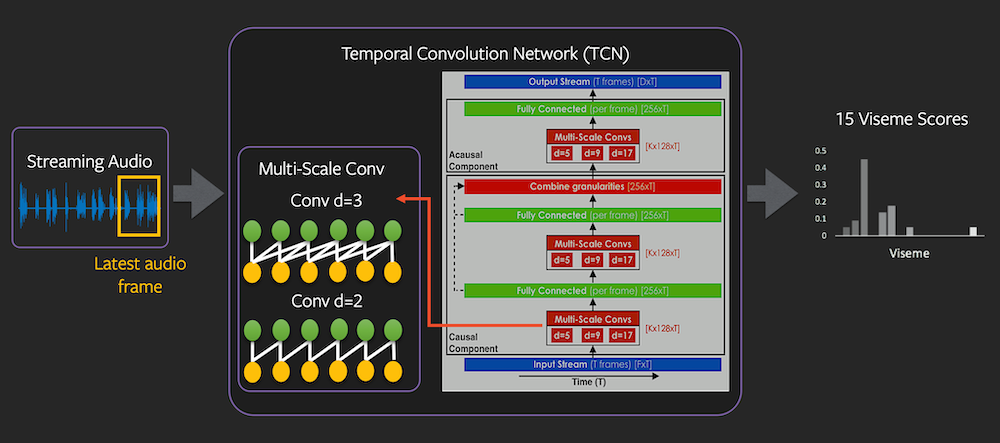
Both the viseme prediction and laughter detection models rely on a Temporal Convolutional Network (TCN) applied to the input stream of 32-dimensional LogMel feature vectors extracted from the raw audio signal. The viseme prediction network first predicts 44 phonemes that are mapped to the 15 viseme mouth shape outputs. The laughter detection network directly predicts the probability of laughter occurring as a floating point value in range 0.0 to 1.0. In the network architecture illustrated below, we can see that convolutions with varying filter sizes (5, 9, 17) are applied across the temporal domain to aggregate audio features at different temporal scales.
One of the primary challenges of developing a robust laughter detector was handling the large variety of laughter sounds that often were ambiguous and hard to identity. To address this challenge we manually labeled and tagged a diverse set of laughter audio recordings and regularly benchmarked the network against subsets of the dataset to ensure strong performance across all types of laughs. Furthermore, we augmented the training dataset with non-laughter noises to improve the network’s robustness. Finally, we optimized the network for real-time inference on CPU or DSP by reducing the number of channels, convolutional filter sizes, and quantizing to int-8.
The Oculus LipSync library is available as a Unity or Unreal Engine Plugin. Please visit the Oculus LipSync Documentation and Guide to learn more about the library and download the SDK.
For more technical details and discussion, see our blog posts for release v1.28.0 and release v1.30.0. Also watch my presentation at Pytorch Developer Conference 2018 for a detailed overview. (My talk begins at time-stamp 31:45)
Technologies
- Pytorch
- Caffe2
- ONNX
- Unity C#
- DNN Quantization