
Kalman Filter
The Kalman Filter is a versatile algorithm, often used to solve problems in subjects such as control, navigation, computer vision, or time series estimation. I’ve applied the Kalman Filter to smooth the keypoint estimates output by a per-frame keypoint detector or optical flow algorithm. In this context, the Kalman Filter is primarily used to reduce the noise introduced by inaccurate detections or predict future keypoint motion.
Definition
The Kalman filter is an algorithm to estimate the state of a variable given a sequence of inaccurate and/or noisy observations. The Kalman filter applied to keypoint tracking can be used to maintain an estimate of the position of the true position (and other relevant state variables such as velocity) of each keypoint despite noisy observations output by the detector per frame.
Given the state , the time evolving process can be described by the recursive equation:
- is the state transition matrix. This matrix is constant and can be derived from kinematics if using a physics model to describe the keypoint.
- relates the control input to the state
The measurements (also referred to as observations) are related to the state by the equation:
- relates the measurement to the state .
- and are process and measurement noise assumed to be independent and normally distributed
The process noise covariance matrix and the measurement noise covariance matrix can change over time. The Kalman filter is not robust to extreme outliers due to the assumption that the process and measurement noise are normal distributed.
Error Estimates
- is the a priori state estimate at step k given knowledge of the process prior to step
- is the a posteriori state estimate at step k given measurement . The a priori and a posteriori estimate errors are
With covariance matrices
A Posteriori state update
The core operation of the Kalman filter is to compute an a posteriori state estimate as a linear combination of the a priori estimate and residual, the difference between the predicted measurement and the actual measurement .
The gain matrix factors in the a priori error covariance matrix and the measurement noise covariance matrix to compute a scaling constant in range 0 to 1 to control the amount of residual that contributes to the a posteriori state estimate. As the Kalman filter’s confidence in the a priori estimate of the state increases (i.e. as decreases), the gain will approach 0. The Kalman filter doesn’t need to incorporate the measurement into its a posteriori estimate of the state since the a priori estimate is assumed to be highly accurate. As similar result will occur if the measurement noise increases. The gain will decrease towards 0, and the residual’s contribution towards the a posteriori state estimate will be less because the observations are noisy and cannot be trusted. On the other hand, if the measurement noise decreases towards 0, the gain will approach 1 and weigh the residual more in the a posteriori state estimate.
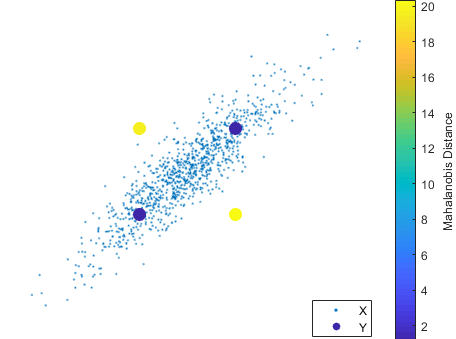
Mahalanobis distance
The mahalanobis distance measures the distance between a point a distribution. More specifically, it measures the number of standard deviations that a point is away from the distribution mean. In the subject of Kalman filtering, the mahalanobis distance between the measurement and the a priori measurement error uncertainty distribution can characterize whether is an outlier.
mahanalobis_distance
- is the a priori measurement error uncertainty distribution, factoring in the a priori estimate error covariance and the measurement noise covariance.
- is the residual between the a priori predicted measurement and the observed measurement .
The mahalanobis distance measures how many standard deviations the measurement is away from the expected a priori value , scaled by the measurement error uncertainty distribution .
Kalman equations
The Time Update “Predict” Step
- Project the state ahead
- Project the error covariance ahead
The Measurement Update “Correct” Step
- Compute the Kalman gain
- Update the estimate with measurement
- Update the error covariance
Technologies
- C++
- Python